数据血缘关系(Data Lineage)是数据治理中的关键概念,它描述了数据从源头到最终使用的完整流转路径,包括数据的来源、转换过程、依赖关系以及最终流向。在当今数据驱动的业务环境中,数据血缘关系解析已成为企业确保数据质量、合规性和可追溯性的核心技术。
一、数据血缘关系的核心价值
- 数据可追溯性:能够快速定位数据问题根源,例如在数据报表出现异常时,通过血缘关系追溯至原始数据源或中间处理环节。
- 影响分析:当数据源或处理逻辑变更时,可准确评估对下游系统的影响范围。
- 合规与审计:满足GDPR、数据安全法等法规要求,提供完整的数据生命周期记录。
- 数据资产管理:帮助企业理解数据资产的价值流转,优化数据架构。
二、数据血缘关系的技术实现方式
- 静态解析:通过分析SQL脚本、ETL工具配置文件、数据建模工具元数据等,提取表级和字段级的血缘关系。
- 动态追踪:在数据流水线执行过程中,通过埋点技术实时捕获数据流转信息。
- 机器学习辅助:利用自然语言处理技术解析数据文档,或通过图算法自动发现潜在的数据关联。
三、典型应用场景
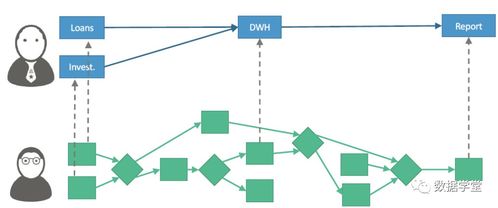
- 数据仓库与数据湖:在数仓建设中,血缘关系可清晰展示数据从ODS到DW再到DM层的加工过程。
- 数据迁移项目:确保迁移过程中数据逻辑的完整性和一致性。
- 数据质量管控:建立数据质量问题的快速定位和修复机制。
- 数据安全治理:实现敏感数据的全程监控与权限管控。
四、实践建议
- 工具选型:根据企业数据架构选择适合的血缘分析工具,如开源方案(OpenLineage)、商业工具或自研平台。
- 标准化建设:建立统一的数据命名规范和处理流程,便于自动化采集血缘信息。
- 渐进式实施:从关键业务系统开始,逐步扩大覆盖范围,避免一次性全面铺开带来的实施难度。
- 组织协同:需要数据工程师、分析师和业务人员共同参与,确保血缘信息的准确性和实用性。
五、未来发展趋势
随着数据 Mesh、Data Fabric 等新架构的兴起,数据血缘关系解析将向更智能化、实时化和自动化的方向发展。同时,与数据目录、数据质量等工具的深度集成,将为企业提供更完整的数据治理解决方案。
数据血缘关系解析不仅是技术实现,更是组织数据文化的重要组成部分。通过系统化的血缘关系管理,企业能够真正实现数据的可知、可信、可控,为数字化转型奠定坚实基础。